谷歌OpenAI竞相发布AI新品,AI技术再升级
AI导读:
3月26日,谷歌推出新一代大语言模型Gemini 2.5,全面超越多个基准测试。随后,OpenAI紧急发布GPT-4o图像生成功能。两大科技巨头竞相发布AI新品,标志着全球AI技术的持续升级。
3月26日凌晨,谷歌正式推出了旗下新一代大语言模型Gemini 2.5,这一举动标志着AI技术的又一重大进展。
谷歌将Gemini 2.5定义为公司迄今为止“最智能的AI模型”,其在多项基准测试中全面超越OpenAI o3-mini、Claude3.7 Sonnet、Grok-3和Deepseek-R1。谷歌DeepMind首席技术官Koray Kavukcuoglu表示,Gemini 2.5代表了谷歌让“人工智能更智能、推理能力更强”的目标的下一步。

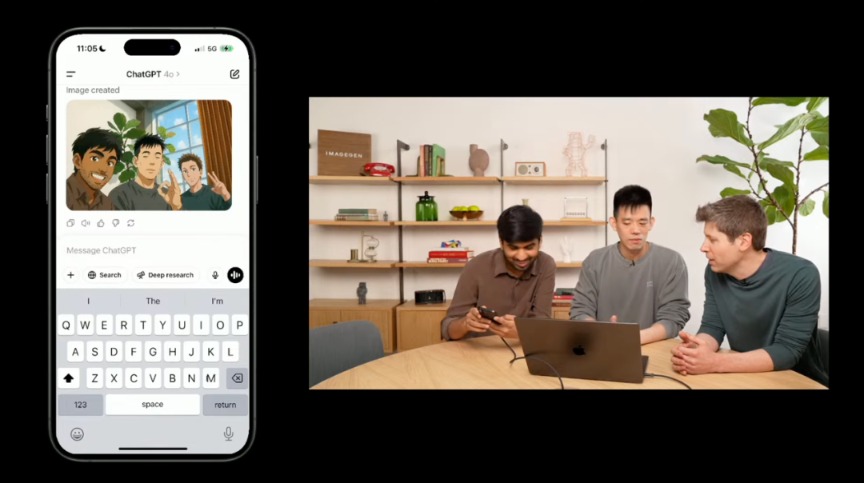
值得注意的是,在谷歌发布Gemini 2.5后不久,OpenAI就紧急发布了最先进的图像生成器GPT-4o。这一图像生成功能可精准文本渲染、严格遵循指令提示,并深度调用GPT-4o知识库及对话上下文。OpenAI创始人兼CEO山姆·奥特曼在直播中展示了GPT-4o的自拍漫画图片生成功能。
谷歌新推理模型,编码推理能力卓越
谷歌长期以来致力于通过强化学习、思维链提示等技术提升AI的推理能力。此次发布的Gemini 2.5系列模型,在编码性能上有了显著提升,擅长创建视觉吸引的网页应用程序和代理代码应用,同时在多项基准测试中领先。
作为挑战OpenAI“o”系列推理模型的尝试,Gemini 2.5 Pro实验版在LMArena上排名第一。其编码能力在SWE-BenchVerified上得分高达63.8%,并能通过单行提示生成可执行代码来创建视频游戏。
在推理能力方面,Gemini 2.5 Pro在“人类的最后考试”等高级推理基准测试中领先,原生多模态处理能力和超长上下文窗口支持多模态输入。

OpenAI紧急推出GPT-4o图像生成功能
面对谷歌的挑战,OpenAI推出了基于GPT-4o模型的全新图像生成功能,这一功能在图像生成时能更加精确地遵循指示、渲染文字,并轻松创作虚实结合的场景。
GPT-4o图像生成功能已向Plus、Pro、Team和免费用户推出,企业和教育用户将很快获得访问权限。该功能能生成手写字、高清图片,并能成为实用的生产力工具,如设计菜单图片等。


然而,OpenAI也承认模型存在限制,如裁剪、幻觉、精确绘图等问题,并计划在首次发布后通过模型改进来解决。
谷歌与OpenAI的竞争,体现了全球AI技术的持续升级。随着AI竞争日趋激烈,各厂商正加快研发速度,未来或将迎来更多技术突破。
(文章来源:证券时报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。






