DeepSeek揭秘推理系统:成本利润率高达545%
AI导读:
DeepSeek首次披露其V3/R1推理系统,假定GPU租赁成本下,理论上一天的总收入可达562027美元,成本利润率高达545%。同时,潞晨科技宣布将在一周后停止提供DeepSeek API服务。
一起关注一下关于Deepseek的最新消息!
DeepSeek首次披露:理论成本利润率高达545%
当市场以为DeepSeek的开源周内容发布完毕后,3月1日,DeepSeek宣布了“One More Thing”,揭秘V3/R1推理系统,并公开了其大规模部署的成本和收益。
根据《DeepSeek-V3/R1推理系统概览》的文章,假定GPU租赁成本为2美元/小时,总成本为87072美元/天;如果所有tokens全部按照DeepSeek R1的定价计算,理论上一天的总收入为562027美元/天,成本利润率高达545%。
据官方披露,DeepSeek-V3/R1推理系统的优化目标是:更大的吞吐,更低的延迟。
为了实现这两个目标,DeepSeek使用大规模跨节点专家并行(Expert Parallelism / EP)。EP使得batch size大大增加,提高GPU矩阵乘法的效率,提高吞吐;同时,专家分散在不同的GPU上,每个GPU只需计算很少的专家,降低延迟。
但EP也增加了系统的复杂性,主要体现在引入跨节点的传输和涉及多个节点需要Data Parallelism(DP)进行负载均衡。
DeepSeek介绍了如何使用EP增大batch size,隐藏传输耗时,进行负载均衡。
由于DeepSeek-V3/R1的专家数量众多,并且每层256个专家中仅激活其中8个,模型的高度稀疏性决定了必须采用很大的overall batch size,以实现更大的吞吐、更低的延时。因此,需要采用大规模跨节点专家并行(Expert Parallelism / EP)。
DeepSeek使用多机多卡间的专家并行策略,以达到Prefill、Decode等目的。
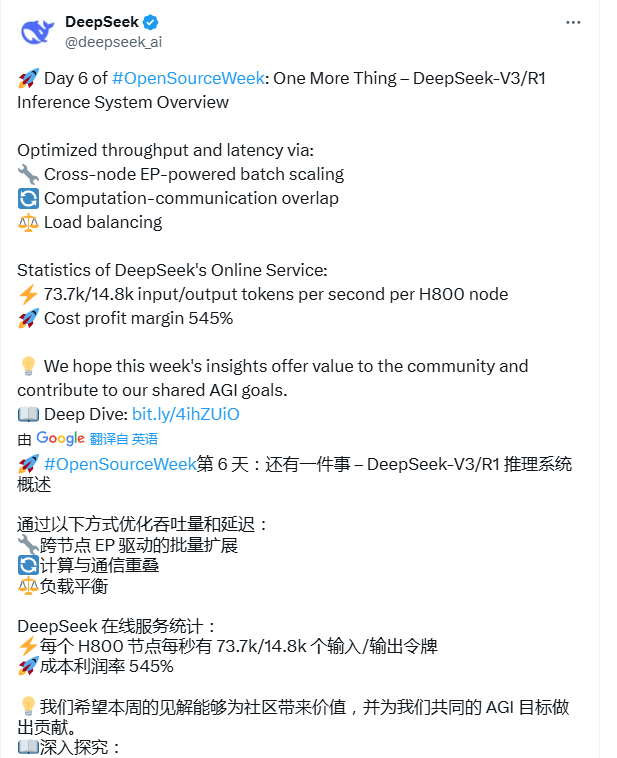
多机多卡的专家并行会引入较大的通信开销,所以DeepSeek使用了双batch重叠来掩盖通信开销,提高整体吞吐。
DeepSeek通过计算和通信的重叠,以及负载均衡策略,尽可能地为每个GPU分配均衡的计算和通信负载。
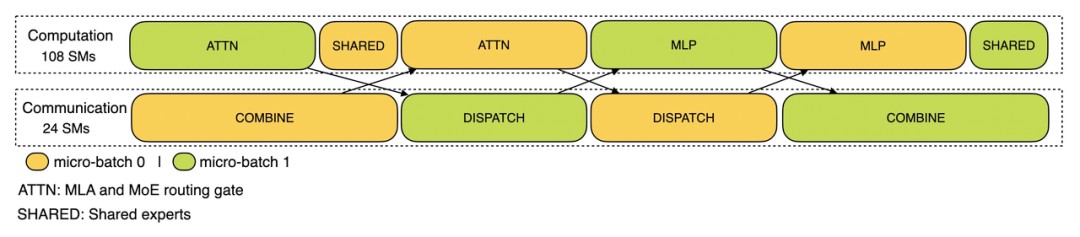
DeepSeekV3和R1的所有服务均使用H800GPU,最大程度保证了服务效果。由于白天的服务负荷高,晚上负荷低,DeepSeek实现了一套机制,在白天负荷高时用所有节点部署推理服务,晚上负荷低时减少推理节点,用于研究和训练。
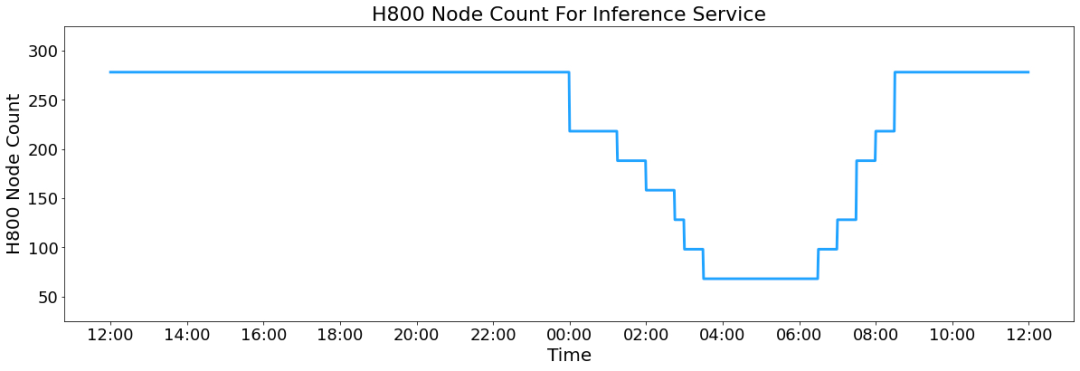
在最近的24小时统计时段内,DeepSeek-V3和R1推理服务占用节点总和,峰值占用为278个节点,平均占用226.75个节点(每个节点为8个H800GPU)。假定GPU租赁成本为2美金/小时,总成本为87072美元/天。
如果所有tokens全部按照DeepSeek-R1的定价计算,理论上一天的总收入为562027美元,成本利润率为545%。当然实际上没有这么多收入,因为V3的定价更低,同时收费服务只占了一部分,另外夜间还会有折扣。
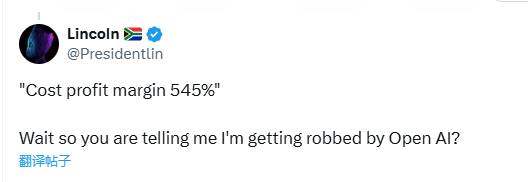
有网友将DeepSeek与OpenAI进行对比,表示:“‘成本利润率545%’,我是说我被OpenAI抢劫了吗?”
潞晨科技暂停DeepSeek API服务
就在DeepSeek披露大规模部署成本和收益之后,潞晨科技突然宣布,将在一周后停止提供DeepSeek API服务,请用户尽快用完余额,没用完的将全额退款。

此前,华为计算微信公众号曾发文表示,DeepSeek-R1系列模型的开源,因其出色的性能和低廉的开发成本,已引发全球的热切讨论和关注。潞晨科技携手昇腾,联合发布了基于昇腾算力的DeepSeek-R1系列推理API及云镜像服务。
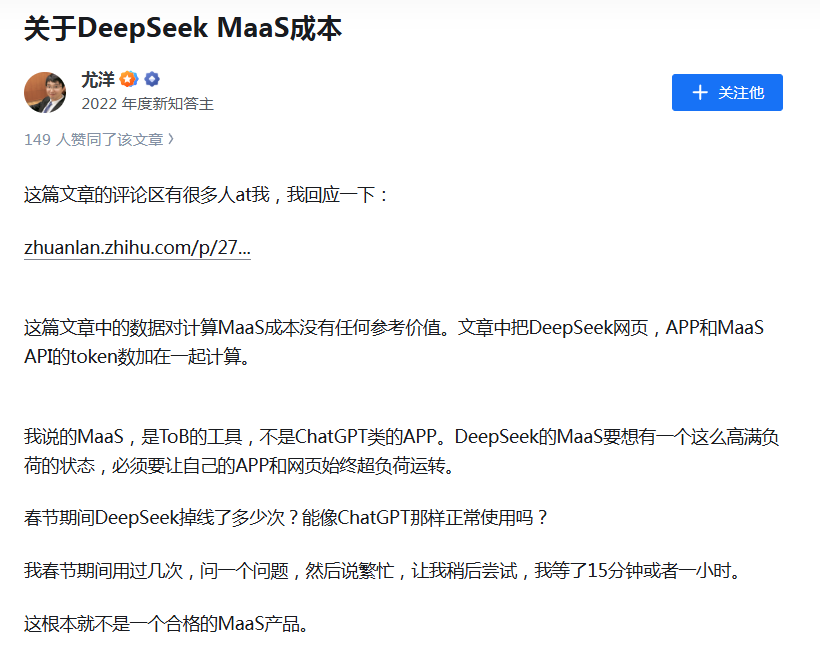
但近期潞晨科技CEO尤洋指出,完成1000亿token的输出,需要约4000台搭载H800的机器,每月仅机器成本就达4.5亿元,因此企业方可能面临每月4亿元的亏损。

潞晨科技CEO尤洋随后发文回应了DeepSeek公布的理论成本利润率。
公开资料显示,潞晨科技是一家致力于“解放AI生产力”的全球性企业,团队核心成员来自美国加州大学伯克利分校、斯坦福大学、清华大学、北京大学等国内外知名高校。公司旨在打造一个开源低成本AI大模型开发系统Colossal-AI,帮助企业最大化人工智能训练效率,最小化训练成本。
(文章来源:中国基金报)
郑重声明:以上内容与本站立场无关。本站发布此内容的目的在于传播更多信息,本站对其观点、判断保持中立,不保证该内容(包括但不限于文字、数据及图表)全部或者部分内容的准确性、真实性、完整性、有效性、及时性、原创性等。相关内容不对各位读者构成任何投资建议,据此操作,风险自担。股市有风险,投资需谨慎。如对该内容存在异议,或发现违法及不良信息,请发送邮件至yxiu_cn@foxmail.com,我们将安排核实处理。





